Reducción de dimensión: Análisis de Componentes Principales¶
Julián D. Arias Londoño¶
Profesor Asociado
Departamento de Ingeniería de Sistemas
Universidad de Antioquia, Medellín, Colombia
julian.ariasl@udea.edu.co
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
En este momento del curso son claras las razones por las cuales puede ser necesario implementar un etapa de reducción de dimensión en un problema de aprendizaje, y las dos alternativas disponibles: Selección/Extracción de Características.
Aunque la selección de características tiene ventajas en comparación con los métodos de extracción, también tiene desventejas, principalmente su alto costo computacional (que se ve agravado si el criterio de selcción es tipo wrapper) y la imposibilidad de garantizar la escogencia del mejor subconjunto de variables y por consiguiente la posible pérdida de información por las variables eliminadas.
El Análisis de Componentes Principales (En inglés Principal Component Analysis - PCA), es una técnica de extracción cuyo objetivo es reducir la dimensión de un conjunto de variables, conservando la mayor cantidad de informaci ́on que sea posible.
En conjuntos de variables con alta dependencia es frecuente que un pequeño número de nuevas variables (menos del 20 % de las originales) expliquen la mayor parte (más del 80 % de la variabilidad original [1]), Por lo tanto PCA realiza la transformación a un nuevo conjunto de variables que son no correlacionadas y se ordenan de modo tal que unas pocas retengan la mayor cantidad de variación presente en el conjunto original de variables.
La medida de información en PCA está asociada entonces al nivel de variación de las variables.
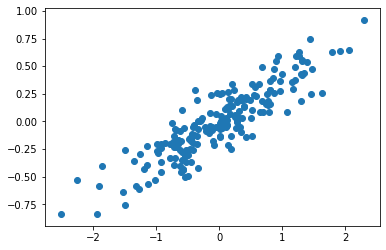
np.random.seed(1)
X = np.dot(np.random.random(size=(2, 2)), np.random.normal(size=(2, 200))).T+10
# center data on 0,0
X=X-np.mean(X, axis=0)
plt.scatter(X[:,0], X[:,1])
<matplotlib.collections.PathCollection at 0x7f2d7edef410>
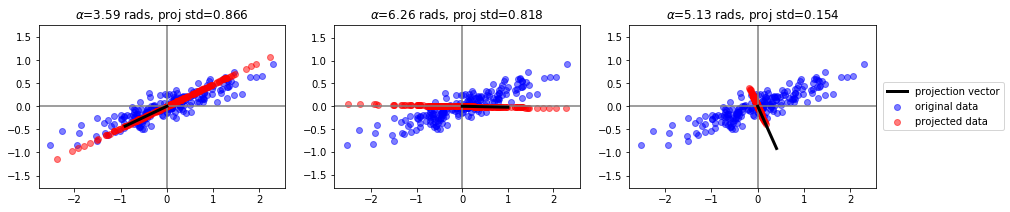
Veamos algunas proyecciones posibles¶
plt.figure(figsize=(15,3))
unit_vector = lambda angle: np.array([np.cos(angle), np.sin(angle)])
for i in range(3):
plt.subplot(1,3,i+1)
angle = np.random.random()*np.pi*2
v = unit_vector(angle)
c = X.dot(v.reshape(-1,1))/(np.linalg.norm(v)**2)
Xp = np.repeat(v.reshape(-1,2),len(X),axis=0)*c
plt.scatter(X[:,0], X[:,1], color="blue", alpha=.5, label="original data")
plt.scatter(Xp[:,0], Xp[:,1], color="red", alpha=.5, label="projected data")
plt.axvline(0, color="gray")
plt.axhline(0, color="gray")
plt.plot([0,v[0]], [0,v[1]], color="black", lw=3, label="projection vector")
plt.axis('equal')
plt.ylim(-2,2)
plt.title("$\\alpha$=%.2f rads, proj std=%.3f"%(angle, np.std(c)))
if i==2:
plt.legend(loc="center left", bbox_to_anchor=(1.01,.5))
Formalmente…¶
Supongamos que contamos con un matriz \(\bf{X}\) que contiene \(N\) muestras cada una de \(d\) variables. Para el cálculo de las proyecciones de PCA es necesario que los elementos de la matriz \(\bf{X}\) tengan media cero, así que suponemos que previamente hemos extraído la media a cada una de las variables. Por lo tanto la matriz de covarianza de los datos está dada por:
Supongamos entonces que inicialmente el objetivo es proyectar todas las muestras observadas sobre un subespacio de dimensión 1 (una recta), de tal forma que todos los puntos mantengan, en la medida de lo posible, sus posiciones relativas, es decir nos interesa conservar la misma estructura de los datos originales pero en una dimensión menor.
Una condición a cumplir es que la distancia entre cada punto y su proyección sea mínima. Si representamos la dirección del plano sobre el cual se van a proyectar los datos por un vector unitario \({\bf{u}}_1 = (u_{11} , ..., u_{1d} )^T\) , la proyección de un punto cualquiera \({\bf{x}}_i\) sobre esta dirección es el escalar:
Graficamente:

Para intentar conservar la estructura original se puede plantear que la distancia entre el punto original y su proyección sea la más corta posible, por lo tanto si \(r_i\) es la distancia entre el punto \({\bf{x}}_i\) y su proyección sobre la dirección \({\bf{u}}_1\), el objetivo es:
Lo que implica encontrar el vector \({\bf{u}}_1\) que maximice \(z_i^{2}\), osea:
Teniendo en cuenta la proyección de toda la matriz \({\bf{X}}\),
El problema de maximización anterior se puede reescribir como:
donde \({\bf{S}}\) es la matriz de covarianza.
Para que el valor de \({\bf{u}}_1\) no crezca indiscriminadamente durante la maximización, es necesario limitar su valor (Lo importante del vector \({\bf{u}}_1\) es su dirección). La restricción se introduce a través de multiplicadores de Lagrange:
Derivando e igualando a cero:
Da como resultado
Esto significa que \({\bf{u}}_1\) es un vector propio de la matriz \({\bf{S}}\) y está asociado al valor propio \(\lambda\).
Si premultiplicamos a ambos lados de la ecuación anterior por \({\bf{u}}_1^T\) nos da como resultado la covarianza de \({\bf{z}}_1\) y como el objetivo es que la varianza sea muy grande, entonces eso implica que el vector propio que debemos seleccionar es aquel que esté asociado al mayor valor propio. En resumen, el vector propio asociado al mayor valor propio \({\bf{S}}\) corresponde al primer componente principal.
En general, es posible hallar el espacio de dimensión \(p<d\) que mejor represente los datos, el cual está dado por los vectores propios asociados a los \(p\) mayores valores propios de \({\bf{S}}\). Estas nuevas direcciones se denominan direcciones principales de los datos y las proyecciones de los datos originales sobre estas direcciones se conocen como componentes principales.

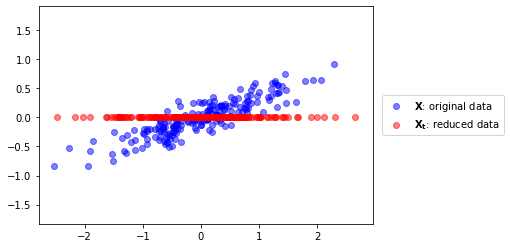
from sklearn.decomposition import PCA
pca = PCA(n_components=1)
pca.fit(X)
Xt = pca.transform(X)[:,0]
plt.scatter(X[:,0], X[:,1], color="blue", alpha=.5, label="$\mathbf{X}$: original data")
plt.scatter(Xt, [0]*len(Xt), color="red", alpha=.5, label="$\mathbf{X_t}$: reduced data")
plt.axis("equal");
plt.legend(loc="center left", bbox_to_anchor=(1.01,.5))
<matplotlib.legend.Legend at 0x7f2d6e7e8b50>
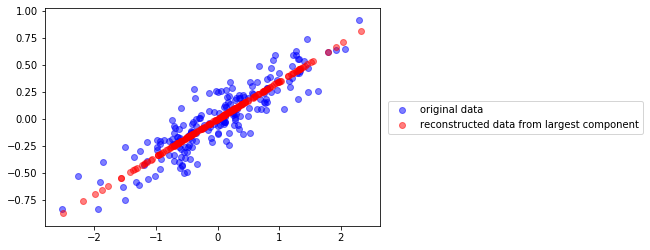
Podemos reconstruir las proyecciones en 2D
u0 = pca.components_[0]
c = X.dot(u0)
Xr = np.r_[[i*u0 for i in c]]
plt.scatter(X[:,0], X[:,1], color="blue", alpha=.5, label="original data")
plt.scatter(Xr[:,0], Xr[:,1], color="red", alpha=.5, label="reconstructed data from largest component")
plt.legend(loc="center left", bbox_to_anchor=(1.01,.5))
<matplotlib.legend.Legend at 0x7f2d6e4fced0>
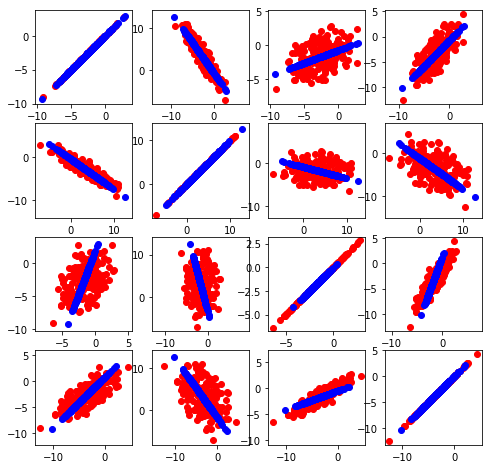
Otros ejemplos…
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
pca = PCA()
Cov = np.array([[2.9, -2.2], [-2.2, 6.5]])
X = np.random.multivariate_normal([1,2], Cov, size=200)
np.random.seed(1)
X_HD = np.dot(X,np.random.uniform(0.2,3,(2,4))*(np.random.randint(0,2,(2,4))*2-1))
print X_HD.shape
(200, 4)
pca = PCA(1) # only keep one dimension!
X_E = pca.fit_transform(X_HD)
print X_E[:10,:]
[[ 1.25150101]
[-0.77555223]
[ 2.93001998]
[ 1.59543949]
[-2.32787353]
[-1.06507191]
[-8.33965885]
[ 2.83034522]
[-7.70257617]
[ 4.53801725]]
X_reconstructed = pca.inverse_transform(X_E)
plt.figure(figsize=(8,8))
for i in xrange(4):
for j in xrange(4):
plt.subplot(4, 4, i * 4 + j + 1)
plt.scatter(X_HD[:,i], X_HD[:,j],c='r')
plt.scatter(X_reconstructed[:,i], X_reconstructed[:,j],c='b')
plt.axis('equal')
Ejemplo en reconocimiento de rosotros (EigenFaces)¶
import pylab as pl
from sklearn.datasets import fetch_lfw_people
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
X = lfw_people.data
y = lfw_people.target
names = lfw_people.target_names
n_samples, n_features = X.shape
_, h, w = lfw_people.images.shape
n_classes = len(names)
def plot_gallery(images, titles, h, w, n_row=3, n_col=6):
"""Helper function to plot a gallery of portraits"""
pl.figure(figsize=(1.7 * n_col, 2.3 * n_row))
pl.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(n_row * n_col):
pl.subplot(n_row, n_col, i + 1)
pl.imshow(images[i].reshape((h, w)), cmap=pl.cm.gray)
pl.title(titles[i], size=12)
pl.xticks(())
pl.yticks(())
plot_gallery(X, names[y], h, w)

from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
print(X_train.shape)
(966, 1850)
from sklearn.decomposition import PCA
n_components = 150
print("Extracting the top %d eigenfaces from %d faces" % (
n_components, X_train.shape[0]))
pca = PCA(n_components=n_components, svd_solver='randomized',whiten=True)
%time pca.fit(X_train)
eigenfaces = pca.components_.reshape((n_components, h, w))
Extracting the top 150 eigenfaces from 966 faces
CPU times: user 568 ms, sys: 1.18 s, total: 1.75 s
Wall time: 122 ms
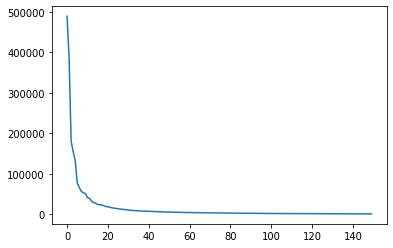
En este caso los componenetes principales se pueden visualizar en forma de imágenes y podemos observar que conservan información de las formas de los rostros y los planos con mayor variación dentro de éstos.
eigenface_titles = ["eigenface %d" % i for i in range(eigenfaces.shape[0])]
plot_gallery(eigenfaces, eigenface_titles, h, w)

plt.plot(pca.explained_variance_);
X_train_pca = pca.transform(X_train)
from sklearn.svm import SVC
svm = SVC(kernel='rbf', class_weight='balanced')
svm
SVC(C=1.0, break_ties=False, cache_size=200, class_weight='balanced', coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import cross_val_score
cv = StratifiedShuffleSplit(n_splits=3, test_size=0.20)
%time svm_cv_scores = cross_val_score(svm, X_train_pca, y_train, scoring='accuracy', n_jobs=2)
svm_cv_scores
CPU times: user 16.8 ms, sys: 4.61 ms, total: 21.4 ms
Wall time: 770 ms
array([0.79381443, 0.78238342, 0.82901554, 0.77720207, 0.80310881])
Realizamos la selección de los mejores parámetros del modelo, en este caso una SVM.
from sklearn.model_selection import GridSearchCV
param_grid = {
'C': [1e3, 5e3, 1e4, 5e4, 1e5],
'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1],
}
clf = GridSearchCV(svm, param_grid, scoring='accuracy', cv=cv, n_jobs=2)
%time clf = clf.fit(X_train_pca, y_train)
print("Best estimator found by randomized hyper parameter search:")
print(clf.best_params_)
print("Best parameters validation score: {:.3f}".format(clf.best_score_))
CPU times: user 326 ms, sys: 8.9 ms, total: 335 ms
Wall time: 7.13 s
Best estimator found by randomized hyper parameter search:
{'C': 1000.0, 'gamma': 0.005}
Best parameters validation score: 0.830
X_test_pca = pca.transform(X_test)
y_pred = clf.predict(X_test_pca)
def title(y_pred, y_test, target_names, i):
pred_name = target_names[y_pred[i]].rsplit(' ', 1)[-1]
true_name = target_names[y_test[i]].rsplit(' ', 1)[-1]
return 'predicted: %s\ntrue: %s' % (pred_name, true_name)
prediction_titles = [title(y_pred, y_test, names, i)
for i in range(y_pred.shape[0])]
plot_gallery(X_test, prediction_titles, h, w)

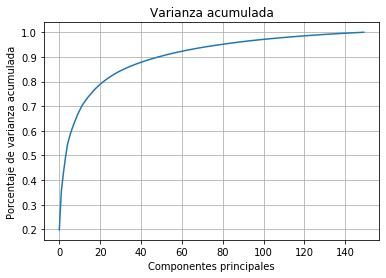
Selección del número de componentes¶
plt.plot(np.cumsum(pca.explained_variance_/np.sum(pca.explained_variance_)))
plt.title('Varianza acumulada')
plt.xlabel('Componentes principales')
plt.ylabel('Porcentaje de varianza acumulada')
plt.grid()